

简洁通用的群体智能引擎,预测万物
A Simple and Universal Swarm Intelligence Engine, Predicting Anything

[](https://github.com/666ghj/MiroFish/stargazers)
[](https://github.com/666ghj/MiroFish/watchers)
[](https://github.com/666ghj/MiroFish/network)
[](https://hub.docker.com/)
[](https://deepwiki.com/666ghj/MiroFish)
[](http://discord.gg/ePf5aPaHnA)
[](https://x.com/mirofish_ai)
[](https://www.instagram.com/mirofish_ai/)
[English](./README.md) | [中文文档](./README-ZH.md)
## ⚡ 项目概述
**MiroFish** 是一款基于多智能体技术的新一代 AI 预测引擎。通过提取现实世界的种子信息(如突发新闻、政策草案、金融信号),自动构建出高保真的平行数字世界。在此空间内,成千上万个具备独立人格、长期记忆与行为逻辑的智能体进行自由交互与社会演化。你可透过「上帝视角」动态注入变量,精准推演未来走向——**让未来在数字沙盘中预演,助决策在百战模拟后胜出**。
> 你只需:上传种子材料(数据分析报告或者有趣的小说故事),并用自然语言描述预测需求
> MiroFish 将返回:一份详尽的预测报告,以及一个可深度交互的高保真数字世界
### 我们的愿景
MiroFish 致力于打造映射现实的群体智能镜像,通过捕捉个体互动引发的群体涌现,突破传统预测的局限:
- **于宏观**:我们是决策者的预演实验室,让政策与公关在零风险中试错
- **于微观**:我们是个人用户的创意沙盘,无论是推演小说结局还是探索脑洞,皆可有趣、好玩、触手可及
从严肃预测到趣味仿真,我们让每一个如果都能看见结果,让预测万物成为可能。
## 🌐 在线体验
欢迎访问在线 Demo 演示环境,体验我们为你准备的一次关于热点舆情事件的推演预测:[mirofish-live-demo](https://666ghj.github.io/mirofish-demo/)
## 📸 系统截图

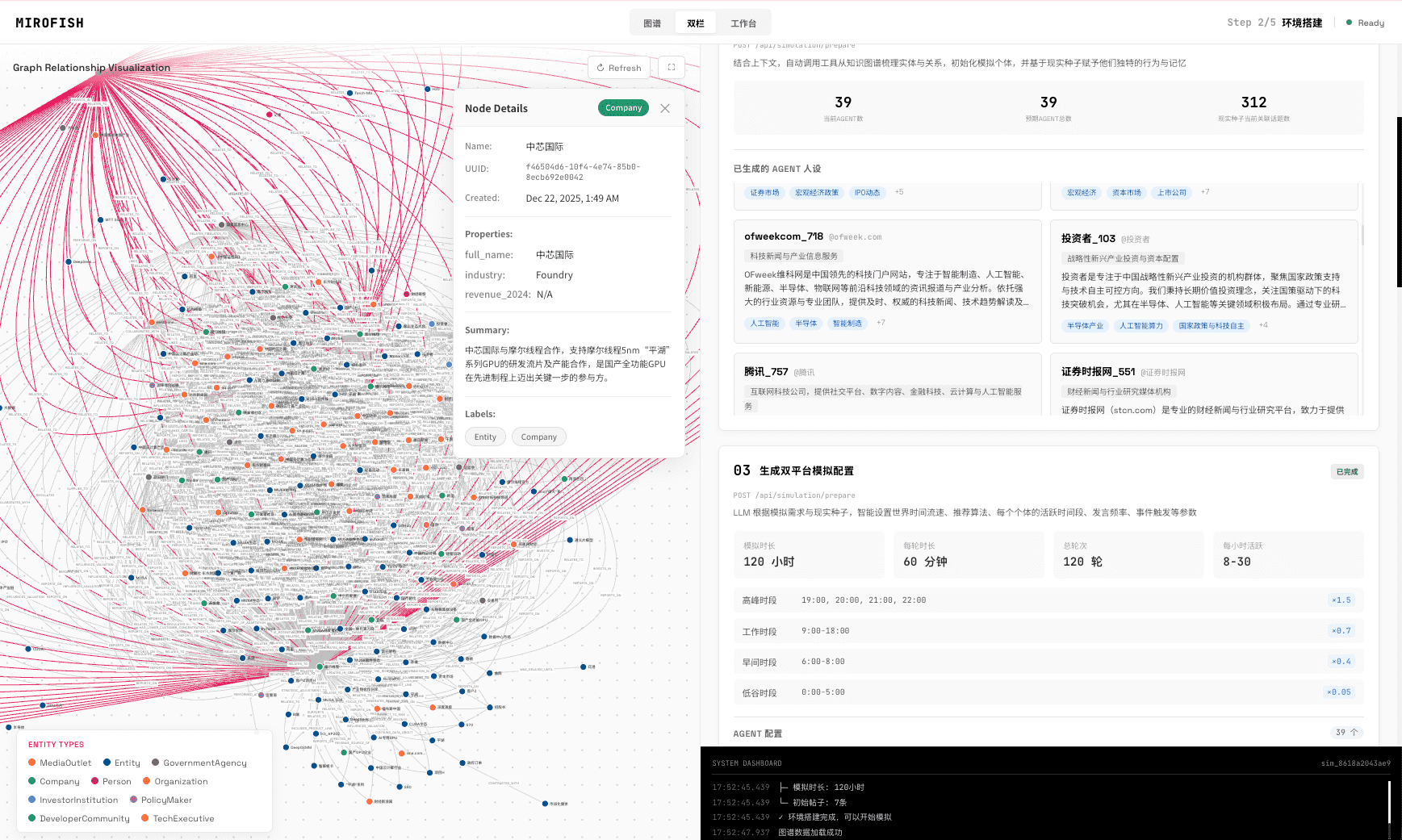
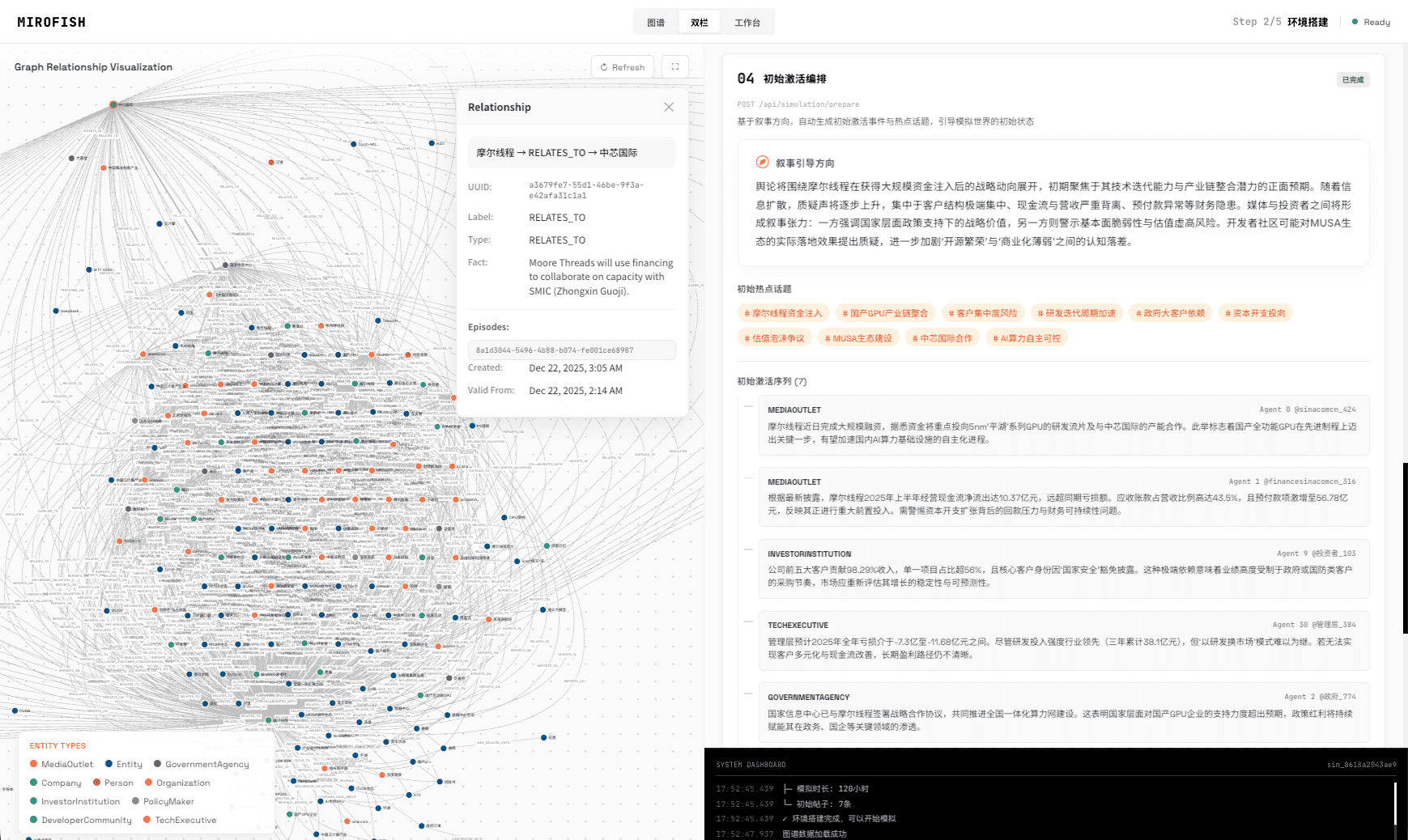
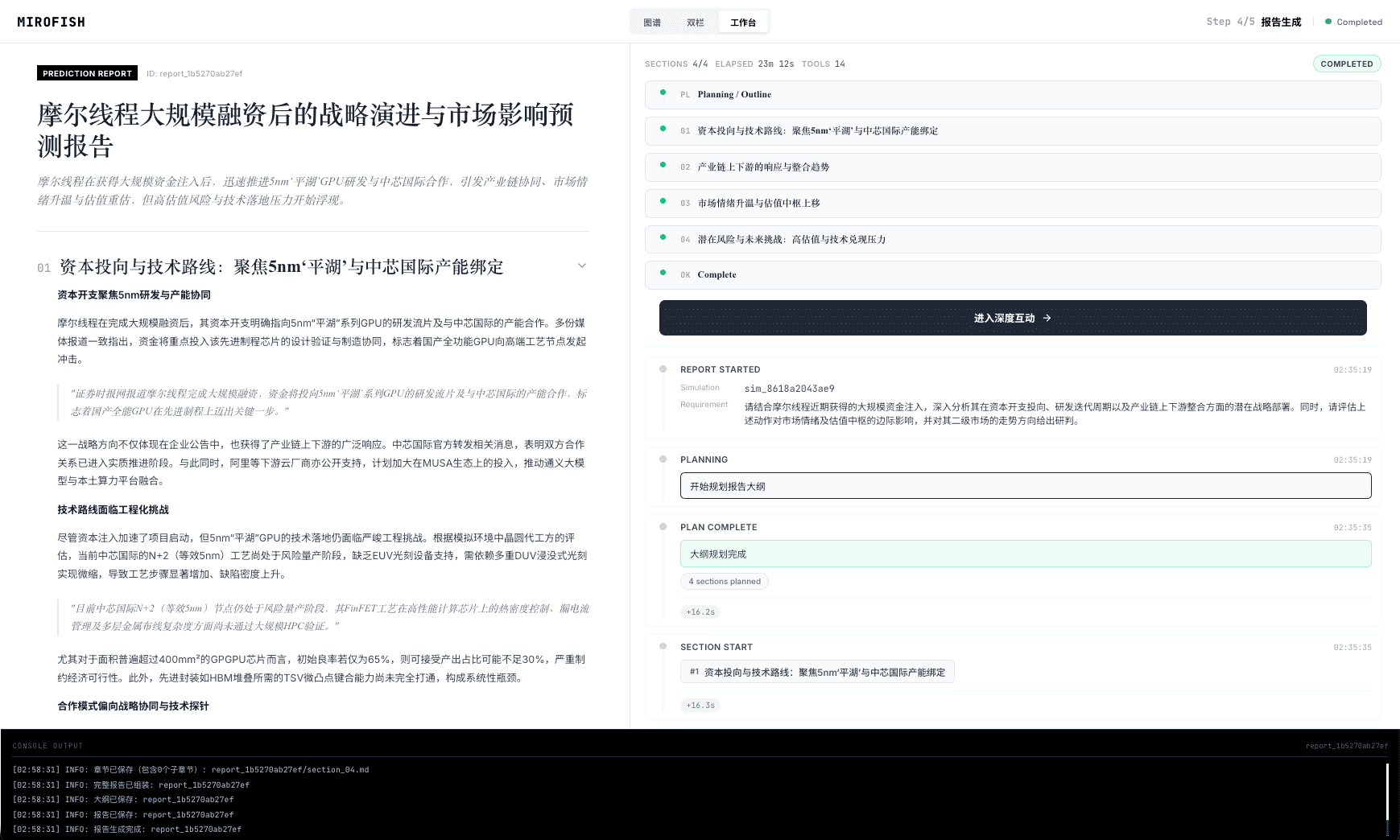
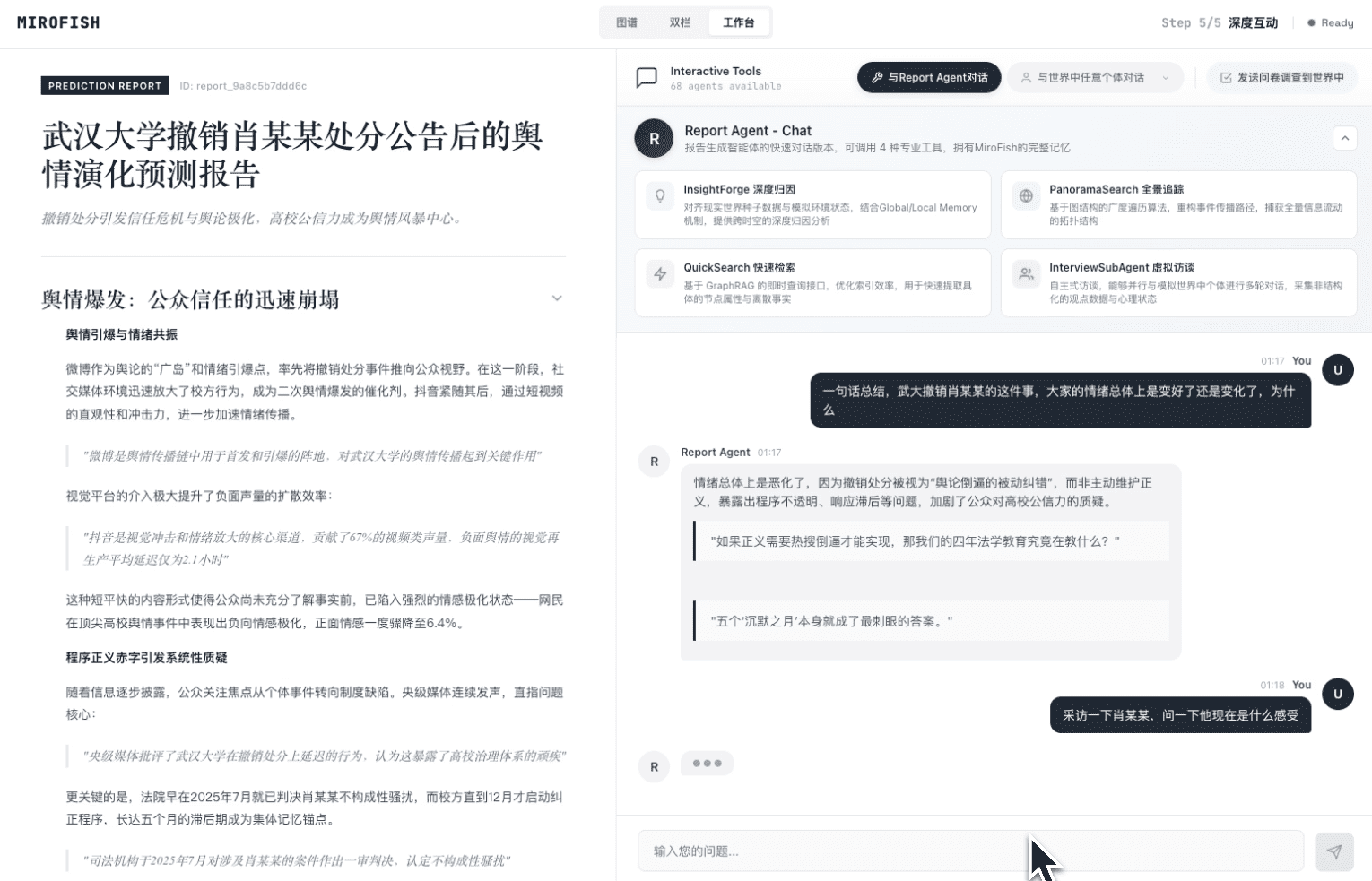
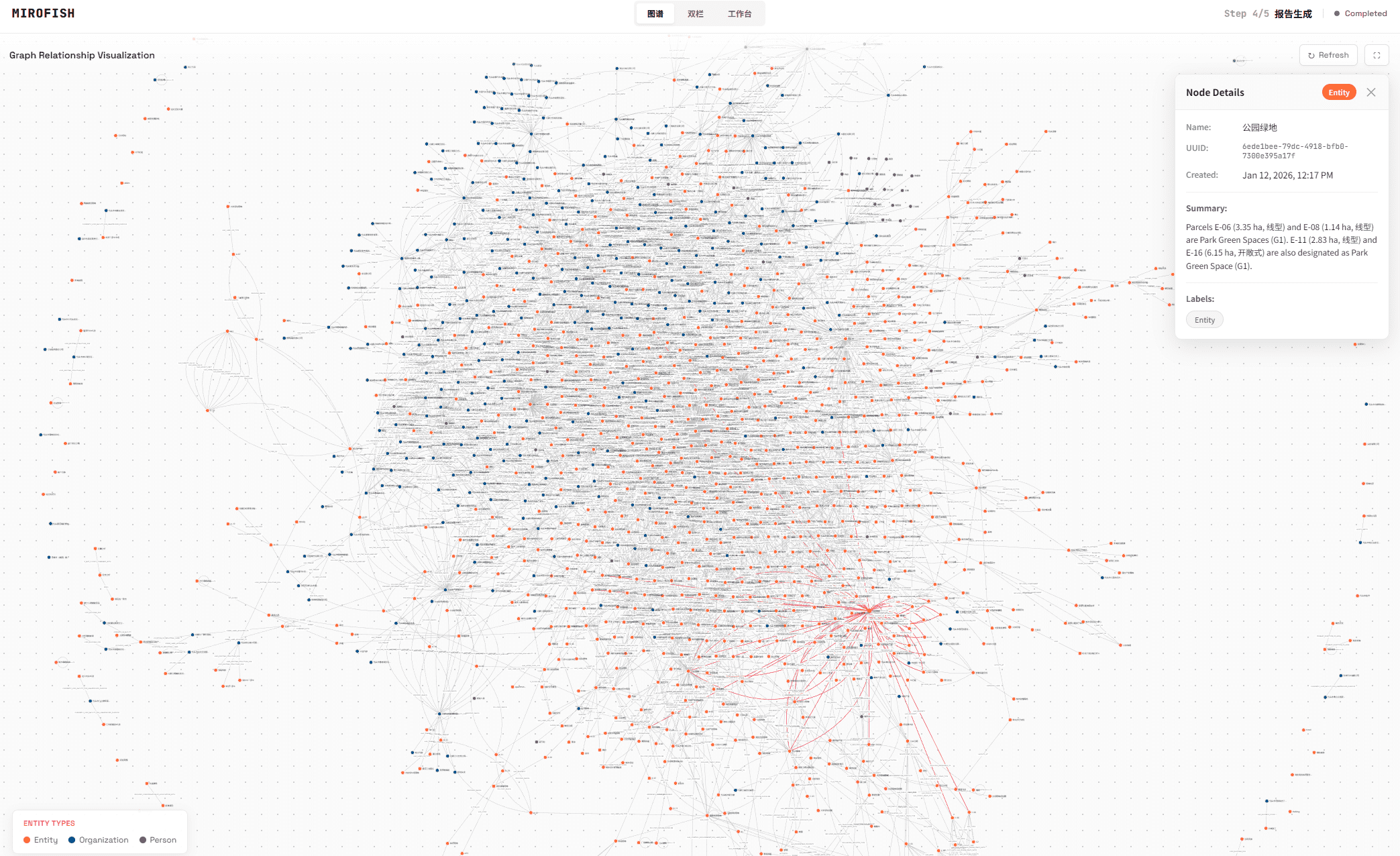
 点击图片查看使用微舆BettaFish生成的《武大舆情报告》进行预测的完整演示视频
点击图片查看使用微舆BettaFish生成的《武大舆情报告》进行预测的完整演示视频
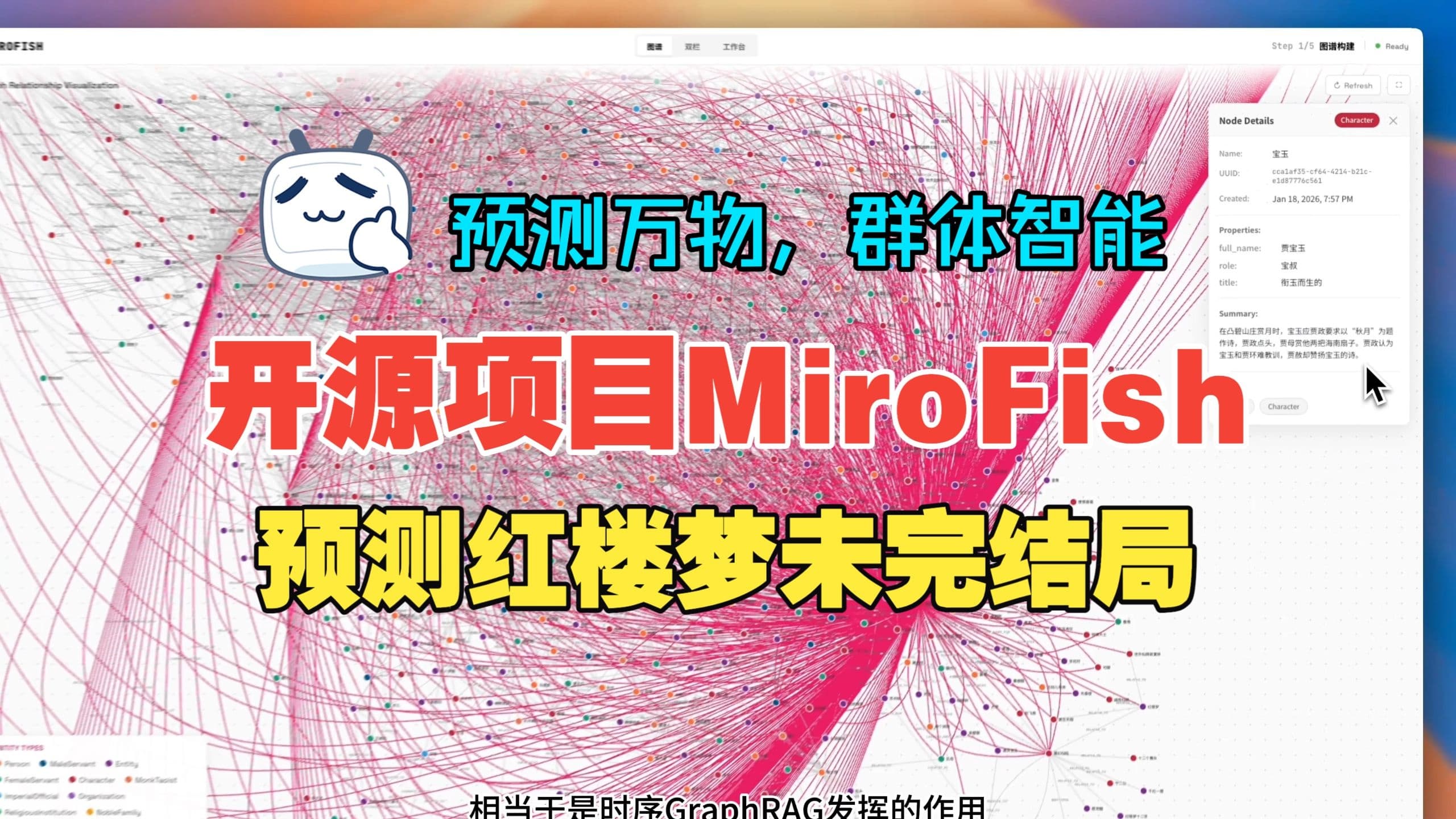 点击图片查看基于《红楼梦》前80回数十万字,MiroFish深度预测失传结局
点击图片查看基于《红楼梦》前80回数十万字,MiroFish深度预测失传结局
